在熟悉了 Observability 的各種概念與工具後,你可能迫不及待想在 Production 中進行實踐。然而,在 Production 環境與在 Lab 環境中實踐 Observability 可以說是完全不同的兩回事。前面的章節中我們著重於資訊的生成與服務的串接,但這些只是基本功。在 Production 環境中,會遭遇多種複雜問題,例如大量的資料、突增的流量、工具的維運、成本考量等。除非你有張永遠刷不爆的信用卡,並且通通依靠 SaaS 服務,否則必須清楚了解這些問題,才能有效地在組織中推動 Observability。
Production 環境中的常見挑戰包括但不限於:
本系列介紹的 Observability 工具大多都是開源的,在不違反授權條款的前提下,我們可以自由的使用這些工具,但不等於不用考慮成本。在 Production 環境中,需考慮的成本包括:
有捨才能有得,付出這些成本,能夠帶來的效益也是相當可觀的:
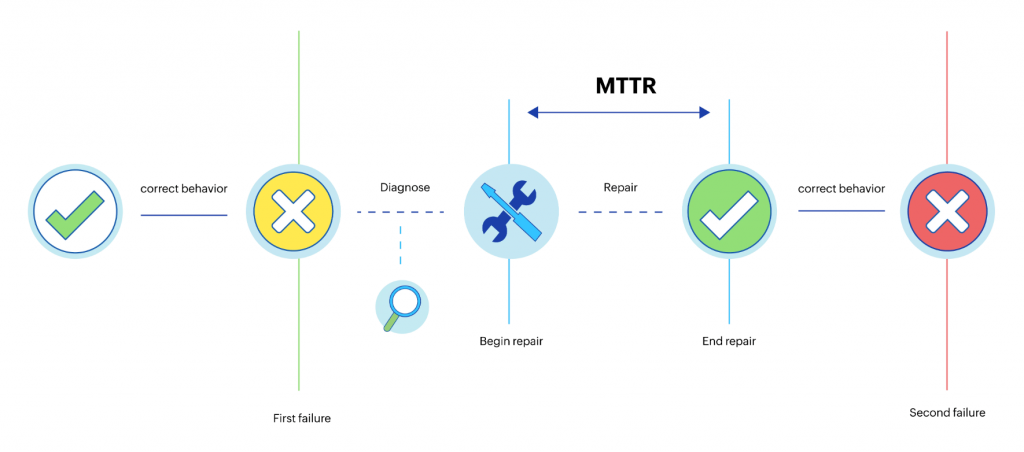
MTTR,Mean Time to Resolution。圖片來源:ManageEngine
相對於成本,效益更難預估。大部分的成本可馬上量化為金額,例如設備金額和投入人力,但效益通常只能在導入後才會顯現。儘管如此,我們可透過過往經驗推估未來效益。舉例來說,計算過去幾次重大事故所造成的商業損失,推測若有 Observability 工具則可避免或減緩其影響。這樣的計算可作為效益的 Baseline,進一步結合其他品質提升效益,明確證明效益大於成本,便能更具說服力地推廣 Observability。
網路的複雜性經常是導入過程中被忽視的問題。各種服務可能透過不同的 Protocol 建立錯綜複雜的連接,而 Production 環境與 Lab 環境相比,服務數量通常是差了好幾個數量級,錯誤的設計除了可能影響資料收集外,還可能拖垮核心的業務服務。為了讓資料收集架構更為簡潔,可能需要搭配 Gateway 或是 Node 上的 Agent 或 Kubernetes 的 DaemonSet 來收集資料。
工具可能支援多種不同 Protocol,如 OpenTelemetry 支援 HTTP 和 gRPC。每種 Protocol 都有其優缺點,因此選擇適合的 Protocol 並深入了解其特性是才能避免後續衍發的配置問題。例如,gRPC 是基於 HTTP/2,因此若需設定 Proxy 應注意是否支援 HTTP/2,否則可能會導致資料無法正常傳輸。
另外,在特定場景中,Production 環境對網路安全有更高要求,如必須使用 TLS 保護所有網路連線。這種情況下,需要注意工具是否支援這類安全機制,以及如何管理相關憑證。
告警疲勞(Alert Fatigue)指的是過量的錯誤告警導致團隊對告警失去敏感度。在評估告警是否有效時,可以使用「混淆矩陣(Confusion Matrix)」評估,詳細如下圖。
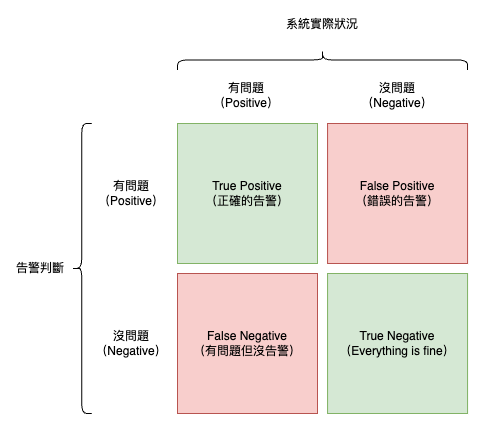
其中 True Positive 代表確實存在的問題也有正常告警,False Positive 則為不正確的告警,這些不正確的告警是引發告警疲勞的主因。另一方面,False Negative 指的是有錯誤發生但沒有觸發告警的狀況,這可能源自於不適當的告警設定或者是尚未被察覺應設定告警的狀態。透過混淆矩陣能夠盤點目前的告警狀況,並進一步針對告警的準確率進行改善。而除了通知維運人員外,各個告警對應的 Runbook 也是必要的,讓每個告警都有個可執行動作,以減緩異常情形,這樣才能確保問題能夠被快速解決。
本篇粗略探討了在 Production 環境中實施 Observability 所面臨的挑戰,這些問題都應予以深入考慮。不過幸好這些挑戰與傳統監控系統所遇到的問題大致相同,因此可借鑑過往的經驗。然而,成本與效益的評估最為關鍵,這不僅是一個技術性問題,更涉及到如何說服組織的方針與資源分配,也是最具挑戰性的一環。
接下來的兩篇文章將分別深入探討「可擴展性(Scalability)」和「長期儲存(Long Term Storage)」的議題。


 iThome鐵人賽
iThome鐵人賽